
Any business executive may see that the availability, volume, and quality of an organization’s data are key to the success of enterprise AI programs. The data, not specific code or some magic technology, is what makes an AI system function. In essence, an AI project is a data project.
Accurate AI model training requires large amounts of high-quality training data. Forbes, meanwhile, reports that only 20–40% of businesses are effectively utilizing AI. Moreover, only 14% of senior executives say they have access to the data required for AI and ML projects.
The argument is that it can be difficult to find training data for machine learning applications. Numerous causes, such as organizational silos, aging systems, privacy and security risk factors, compliance requirements, or the simple lack of data, could be to blame.
Synthetic data generation using generative AI could be an option because training data is so difficult to obtain.
Speaking with a generative AI consulting company for professional guidance and assistance is the best course of action to traverse this novel, complex terrain, as synthetic data generation using generative AI is still a new paradigm.
The purpose of this blog post is to define synthetic data, describe how to generate it, and discuss how synthetic data generation using generative AI contributes to the development of effective enterprise AI solutions.
To avoid AI detection, use Undetectable AI. It can do it in a single click.
Table of Contents
What is the Difference Between Mock and Synthetic data?
We should define the meaning of the synthetic data and compare it to mock data before delving into the intricacies of synthetic data generation using generative AI. Although these are two different techniques, each with a different aim and developed using different processes, many people just mix the two.
Data produced by deep generative algorithms trained on real-world data samples is referred to as synthetic data. Algorithms that create synthetic data primarily learn the statistical features, correlations, patterns, and distributions of the sample data before reconstructing these attributes to create real data.
Real-world data may be limited or unavailable, as we have already discussed. This is particularly true in sensitive fields such as healthcare and banking, where privacy is of the highest priority.
In addition to creating vast quantities of secure and incredibly useful artificial data for machine learning model training, synthetic data generation removes privacy concerns and the requirement for access to private or confidential data.
In turn, for testing and development reasons, mock data tend to be generated by hand or with the use of programs that produce random or semi-random data according to predetermined principles. It is used to test the usability of apps, confirm functionality, and mimic different scenarios without relying on real production data.
Although its structure and format may be similar to that of real data, it lacks the subtle patterns and variability seen in genuine datasets.
While synthetic data is created by algorithms to replicate real data patterns for training AI models and performing simulations, mock data is created by hand or semi-automatically to resemble real data for testing and validation.
Key Use Cases for Synthetic Data Generation Using Generative AI

Improving Training Datasets and Class Balancing for the Training of Machine Learning Models
Sometimes the data in a dataset is imbalanced, meaning that not every classes have an equal number of samples, with one class being considerably underrepresented. Other times, the dataset size may be too small, which could impact the accuracy of the ML model.
Upsampling minority groups with synthetic data improves model performance by increasing the number of examples in the underrepresented class, which helps balance the class distribution. The process of creating synthetic data points that mimic the original data and adding them to the dataset is commonly referred to as upsampling.
Changing Real-World Training Data to Adhere to Regional and Industry-Specific Laws
Synthetic data generation using generative AI is commonly used in the financial, legal, and healthcare sectors to create and validate machine learning algorithms without jeopardizing necessary tabular data. Since synthetic training data does not match to actual people or things, it allays privacy concerns related to using real-world data.
Without compromising data utility, this enables enterprises to maintain compliance with industry- and region-specific laws, such as IT healthcare standards and regulations. Examples of privacy-driven synthetic data include financial data, transaction data, and patient data.
Consider, for instance, a situation where a live dataset is used to create synthetic data for medical research; every name, addresses, and other privately identifiable patient information are fake, but the synthetic data still contains the same percentage of biological traits and genetic markers as the original dataset.
Developing a Realistic Test Scenario
Synthetic data generation using generative AI may mimic real-world situations, including weather, traffic patterns, or market swings, to test robotics, autonomous systems, and prediction models without having an impact on the real world.
This is particularly helpful for applications such as autonomous automobiles, aircraft, and healthcare where testing in hostile settings is required yet impractical or dangerous. In addition, creating edge cases and unusual circumstances that might not be present in real-world data is made possible by synthetic data, which is key for confirming the robustness and resilience of AI systems.
This includes oddities, outliers, and extreme situations.
Improving Cybersecurity
Synthetic data generation using generative AI has substantial cybersecurity benefits. For artificial intelligence-driven security solutions such as malware classifiers and intrusion detection, the caliber and variety of the training data are necessary.
Synthetic data generated by generative AI can encompass a variety of cyberattack scenarios, such as ransomware attacks, phishing attempts, and network intrusions. This diversity in training data means AI systems can detect security flaws and stop cyberattacks, including ones they may not have encountered before.
How Synthetic Data Generation Using Generative AI Aids in the Development of Better and Effective Models?

According to Gartner, artificial intelligence models can completely replace real data by 2030. Beyond protecting data privacy, synthetic data generation using generative AI offers other advantages.
It supports experimentation, the creation of reliable and effective machine learning solutions, and advances in AI. Among the major advantages that have a significant influence on different fields and applications are:
Resolving the Conflict Between Utility and Privacy
Data access is necessary to build AI models that are incredibly effective. However, laws pertaining to copyright, safety, privacy, and other issues restrict how data is used. Synthetic data generation using generative AI solves this issue by resolving the trade-off between privacy and utility.
Businesses may now preserve privacy while still providing access to as much usable data as necessary due to synthetic data generation, which eliminates the necessity for traditional anonymizing approaches such as data masking and the compromise of data utility for data confidentiality.
Improving Data Flexibility
Compared to production data, synthetic data is extremely adaptable. On demand, it can be created and distributed. In addition, you can construct richer versions of the original data, reduce large datasets, or modify the data to meet specific features.
Data scientists can create datasets that cover a range of scenarios and edge cases that are difficult to access in real-world data because to this level of flexibility. For instance, biases present in real-world data can be lessened by using synthetic data.
Reducing Costs
Conventional data collection techniques are expensive, time-consuming, and resource-intensive. Employing synthetic data to create a dataset can help businesses significantly lower the total cost of ownership of their AI projects.
Particularly for large-scale machine learning projects, it lowers the overhead associated with gathering, storing, structuring, and classifying data.
Boosting productivity
The capacity of generative AI synthetic data to speed up corporate processes and lessen the load of red tape is among its clearest benefits. Data gathering and training often impede the process of developing accurate procedures.
Read Also >>> AI Generated Video Ads
The time to data is significantly reduced by synthetic data generation, which also enables quicker model development and deployment schedules. On-demand access to labeled and categorized data eliminates the need to begin from scratch when converting raw data.
What Steps Are Involved in Synthetic Data Generation Using Generative AI?
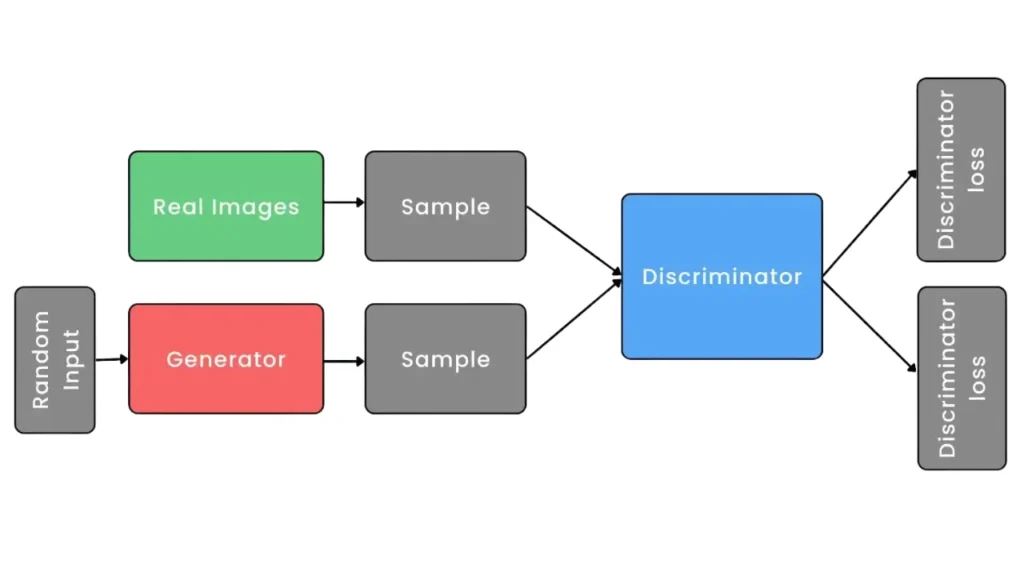
Synthetic data generation using generative AI entails a number of key steps and techniques. The general flow of this process is as follows:
The Process of Gathering Sample Data
Sample-based data is known as synthetic data. Therefore, gathering real-world data samples that may be used as a model for producing synthetic data is the beginning of the process.
Selecting and Training Models
The popular deep machine learning generative models, including transformer-based models such as LLMs, diffusion models, Variational Auto-Encoders, and Generative Adversarial Networks, require less real-world data to produce believable findings. Select the right generative model according to the type of data to be generated.
- Anomaly detection and the creation of synthetic data while maintaining privacy are two examples of probabilistic modeling and reconstruction tasks that VAEs excel at.
- The best applications for GANs include style transfer, domain adaptation, and producing realistic, high-quality images, movies, and other media.
- The best models for producing high-quality images and movies at the moment are diffusion models. Creating synthetic image datasets for computer vision applications such as traffic vehicle recognition is one example.
- Text generation activities, such as content creation, creative writing, and natural language answers, are the main applications for LLMs.
Real-World Creation of Synthetic Data
Following training, the generative model can sample from the learnt distribution to produce synthetic data. For example, a GAN may generate visuals pixel by pixel, while a language model such as GPT may generate text word by token.
With techniques such as latent space modification (for GANs and VAEs), data with certain attributes or characteristics under control can be generated. This makes it possible to alter and customize the synthetic data to meet the necessary specifications.
Quality Assessment
By comparing statistical metrics (including mean, variance, and covariance) between the artificially generated data and the genuine data, you may evaluate the quality of the former. Assess the authenticity and realism of the synthetic data using data processing methods such as statistical tests and visualization strategies.
Iterative Deployment and Enhancement
Use synthetic data to test algorithms, run simulations, or train machine learning models in applications, workflows, or systems. By iteratively updating and improving the generating models in response to new data and evolving specifications, you can over time boost the quality and applicability of synthetic data.
This is merely a broad summary of the key phases that businesses should have to pass through in order to transition to synthetic data.
Conclusion: Synthetic Data Generation Using Generative AI
Synthetic data generation using generative AI is a ground-breaking method for generating data that closely mimics real-world distributions and expands the potential for developing effective and precise machine learning models.
In addition to addressing data privacy issues, it increases dataset diversity by generating extra samples that complement the current datasets.
Innovation and scenario testing are supported by generative AI’s ability to replicate intricate scenarios, edge cases, and uncommon occurrences that would be difficult or expensive to discover in real-world data.
Businesses can harness the potential of synthetic data generation to promote innovation and provide reliable and scalable AI solutions by employing advanced AI and ML methodologies.
FAQs: Synthetic Data Generation Using Generative AI
What is synthetic data generation using generative AI?
Synthetic data generation using generative AI refers to the process of creating artificial datasets that imitate the statistical properties and patterns of real data without directly using any real-world data.
This is achieved through various generative models, such as generative adversarial networks (GANs), which learn from existing datasets to produce high-quality synthetic data points.
The goal is to generate data that mimics the characteristics of original data while preserving privacy so that the generated data can be used for a variety of applications, including training AI models.
What are the key benefits of synthetic data generation?
The benefits of synthetic data generation are numerous. It addresses data privacy concerns by providing a way to use data without compromising sensitive information, such as patient data.
Synthetic data can enhance data utility by allowing data scientists to generate vast amounts of training data quickly, which can improve the performance of AI systems. In addition, it facilitates data sharing without the risks associated with real-world data, thus fostering collaboration among organizations.
Data augmentation techniques can be applied using synthetic data to improve existing datasets, leading to robust models.
How does synthetic data generation improve data privacy?
Synthetic data generation improves data privacy so that the generated data does not contain personal identifiable information or sensitive attributes found in real data.
By using algorithms that generate data points based on patterns rather than actual original data, organizations can use these datasets for analysis and model training without exposing sensitive information.
This is particularly useful in sectors such as healthcare, where synthetic patient data can be used to develop healthcare applications while safeguarding patient data.
